Abstract
Score Distillation Sampling (SDS) by well-trained 2D diffusion models has shown great promise in text-to-3D generation. However, this paradigm distills view-agnostic 2D image distributions into the rendering distribution of 3D representation for each view independently, overlooking the coherence across views and yielding 3D inconsistency in generations.
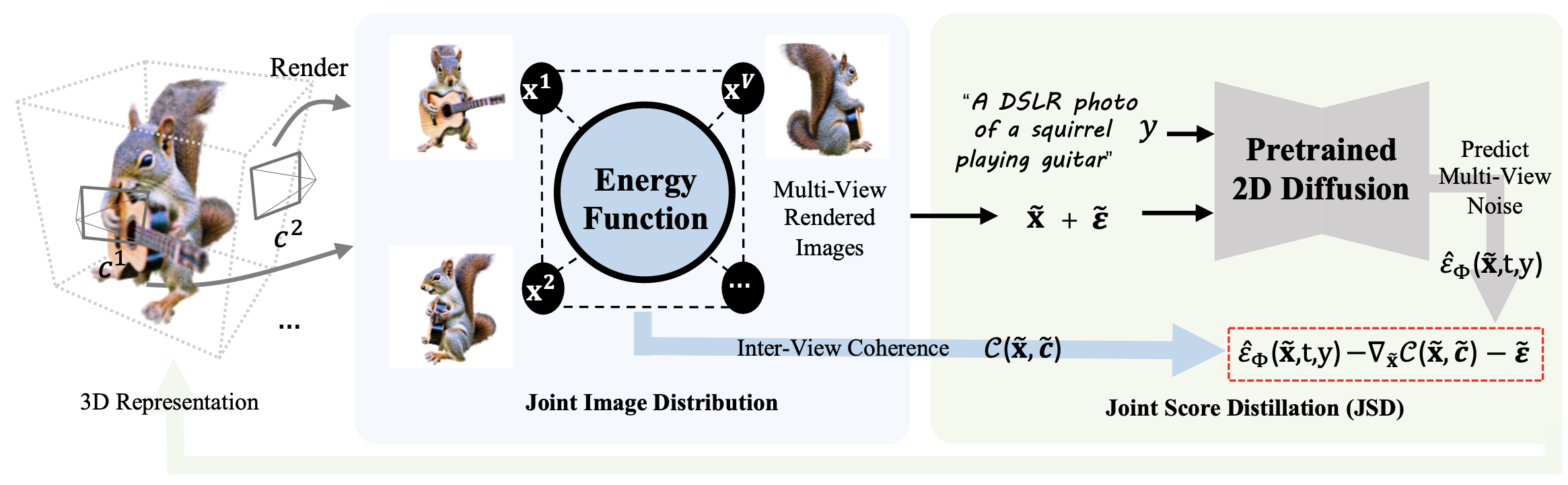
In this work, we propose Joint Score Distillation (JSD), a new paradigm that ensures coherent 3D generations. Specifically, we model the joint image distribution, which introduces an energy function to capture the coherence among denoised images from the diffusion model. We then derive the joint score distillation on multiple rendered views of the 3D representation, as opposed to a single view in SDS. In addition, we instantiate three universal view-aware models as energy functions, demonstrating compatibility with JSD.
Empirically, JSD significantly mitigates the 3D inconsistency problem in SDS, while maintaining text congruence. Moreover, we introduce the Geometry Fading scheme and Classifier-Free Guidance (CFG) Switching strategy to enhance generative details. Our framework, JointDreamer, establishes a new benchmark in text-to-3D generation, achieving outstanding results with an 88.5\% CLIP R-Precision and 27.7\% CLIP Score. These metrics demonstrate exceptional text congruence, as well as remarkable geometric consistency and texture fidelity.